常用快捷键
Mac自带截图功能
Command + Shift + 4普通截图Command + Shift + 4,然后按空格,对指定窗口截图Command + Shift + 3全屏截图
finder显示隐藏文件
Command + Shift + .
Mac瘦身
最好的工具mac-cleanup-sh
~/Library/Application Support/Code/User/workspaceStorage: VS Code的工作区文件夹唉,但是所有的扩展都会重建这个文件夹,把年代久远的删除了
Shell配置使用
Mac使用Iterm2的Profile功能实现类似ssh标签/xshell登录的功能
在Preferences中不仅可以设置默认Profile的窗口样式等,还是通过新建不同的Profile来实现自动登录。例如: 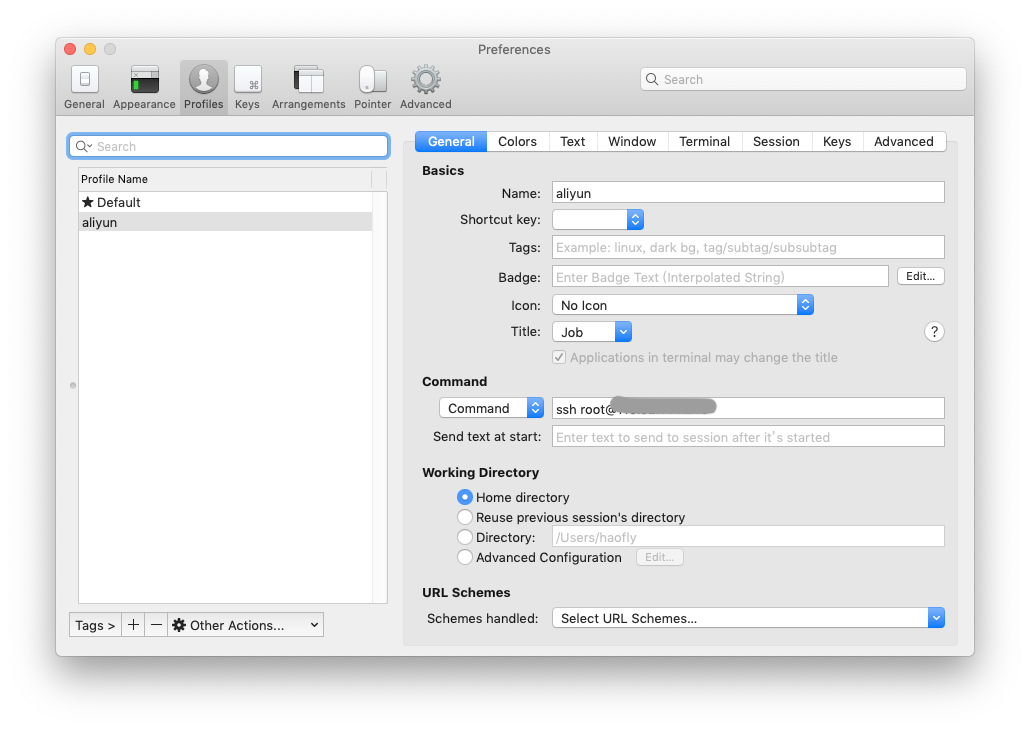
这样如果想要进入某个服务器,只需要在iterm2中点击顶部菜单Profiles->aliyun即可直接进入服务器。对于复杂的输入密码的场景,可以参考Linux 手册的expect进行配置
mac shell使用rz、sz直接上传或者下载服务器文件
- 需要注意的是在使用
except登录服务器的情况下,使用lrzsz不会起作用
首先使用brew install lrzsz安装命令行工具
然后保存iterm2-send-zmodem.sh 和iterm2-recv-zmodem.sh两个脚本到/usr/local/bin目录下
打开iterm2,Perferences->Profiles->Advanced->Triggers->Edit,添加如下trigger
1 | \*\*B0100 Run Silent Coprocess /usr/local/bin/iterm2-send-zmodem.sh |
Homebrew配置使用
- brew如果加cask参数表示下载的是.dmg/.pkg文件,不需要install等操作
1 | export ALL_PROXY=socks5://127.0.0.1:1080 # homebrew走ss代理 |
查看每个CPU的负载/GPU负载
活动监视器->窗口->CPU使用率/CPU历史记录/GPU历史记录
修改终端欢迎字符
1 | vim /private/etc/motd # 直接输入即可 |
系统管理命令
1 | lsof |
更换文件图标
http://www.cnblogs.com/wormday/archive/2011/05/06/2038703.html
与Android联动
brew cask install android-file-transfer可以管理小米手机上的文件
自制iPhone铃声
Mackup配置备份
1 | brew install mackup |
ios safari移动端真机调试
https://channaly.medium.com/how-debug-cordova-based-application-with-chrome-dev-tool-43e095a735b4
- 可用于调试
Cordova/Inoic/Phonegap等hybrid项目
- ios移动端配置:
Settings -> Safari -> Advanced, 打开JavaScript和Web Inspector - mac上safari浏览器配置:
Preferences -> Advanced -> Show Develop menu in menu bar - 当连接上设备后就可以点击
Safari->Develop->iPhone选择你的设备即可
android通过蓝牙向Mac/macbook传输文件失败
- 需要在
电脑左上角apple logo -> System Preferences -> Sharing -> Bluetooth Sharing打开并设置读写权限
iPad或者iPhone投屏到Mac
- iPad数据线连接Mac
- Mac上打开QuickTime Player,然后选择
File -> New Movie Recording,在中间录像按钮边上点开的下拉菜单选择你的设备
安装python2或者python3
不要期待brew,最好直接从官网下载对应版本的dmg文件安装,都可以直接安装的,如果要使用多个不同的版本,也可以使用pyenv:
1 | brew install pyenv |
Mac OS降级
降级最简单的是直接从timemachine恢复,但是大多数情况下我们并没有timemachine,那么就需要U盘了
首先需要从苹果官方下载老版本的系统
然后执行以下命令制作系统盘,执行完成后会提示
Done.,如果多次尝试仍然报错,那么可能需要换个更大的U盘,或者换一个U盘。(我最开始用的16G的USB2.0,后来换成32G的USB3.0就可以了)1
2其中Catalina.app是下载的系统的名称,MyVolume是U盘名称
sudo /Applications/Install\ macOS\ Catalina.app/Contents/Resources/createinstallmedia --volume /Volumes/MyVolume开机时按住Option键,然后选择U盘进入,然后用磁盘工具格式化磁盘,重装系统即可
TroubleShooting
磁盘空间爆了,重启后spotlight一直显示正在索引: 原因可能是误删了索引的文件(索引文件确实有哦几个G),修复需要执行以下几个命令:
1
2
3sudo mdutil -i off /
sudo mdutil -E /
sudo mdutil -i on /Library not loaded: /usr/local/opt/readline/lib/libreadline.6.2.dylib Referenced from: /usr/local/bin/gawk Reason: image not found: 执行下面这个命令更新所有
brew安装的包可以修复1
brew upgrade
明明安装了xcode命令行工具却还是提示找不到,可以用这个命令重装一下:
1
2
3xcode-select --print-path # 一般会打印/Library/Developer/CommandLineTools
sudo rm -r -f /Library/Developer/CommandLineTools
xcode-select --install # 重新安装Macos使用ssh登陆linux服务器无法显示中文,需要设置终端的字符集:
1
2
3vim ~/.zshrc,在底部输入如下内容,然后保存重启终端
export LC_ALL=en_US.UTF-8
export LANG=en_US.UTF-8autoreconf: command not found:
brew install autoconf && brew install automake**xcrun: error: invalid active developer path, missing xcrun **: 重装xcode工具:
xcode-select --installmacOS Big Sur无法使用VPN: 系统限制没办法,得修改VPN服务器的配置,参考苹果的官方说明
telnet: command not found:
brew install telnetSafari不能审查元素,没有审查元素按钮:得手动打开开发者菜单:
Preferences -> Advanced -> Show Develop menu in menu bar新版本是Show features for web developerMacOs安装指定的java版本: https://www.azul.com/downloads/?package=jdk
zsh: bad CPU type in executable: 执行
softwareupdate --install-rosetta